About
I build reasoning systems—for math, code, and decision-making. My recent work focuses on advancing the reasoning capabilities of the Gemini family, including Gemini and Gemini 2.5, where I have been a key contributor to reasoning research. Previously my research centered on causality & modularity in deep learning; today my work is broadly focused on strengthening the reasoning capabilities of large models across many domains.
I completed my PhD at Mila with Professors Yoshua Bengio and Chris Pal. During my PhD I also spent time at Google DeepMind, Facebook/Meta AI Research, and Microsoft Research Montreal. I was named a Rising Star in Machine Learning and a Rising Star in EECS, and received the Facebook Fellowship.
Selected Work
Advanced reasoning, multimodality, long-context understanding, and agentic capabilities in the Gemini 2.5 release.
Highlights Gemini’s mathematical reasoning performance at International Mathematical Olympiad standard.
Invited Talks
- IROS 2023 – Learning to Learn Causal Structure in Reinforcement Learning at the Causality for Robotics workshop.
- NeurIPS 2022 – Learning Neural Causal Models at the Causality for Real-world Impact workshop.
- ICLR 2022 – Modularity, Causality and Deep Learning at the Elements of Reasoning workshop.
- CogX 2020 – Causality in Deep Learning. Speaker page.
- ICML 2022 – Tutorial: Causality & Deep Learning: Synergies, Challenges and the Future. Materials.
- UAI 2022 – Tutorial: Causality & Deep Learning: Synergies, Challenges and the Future. Materials.
Papers
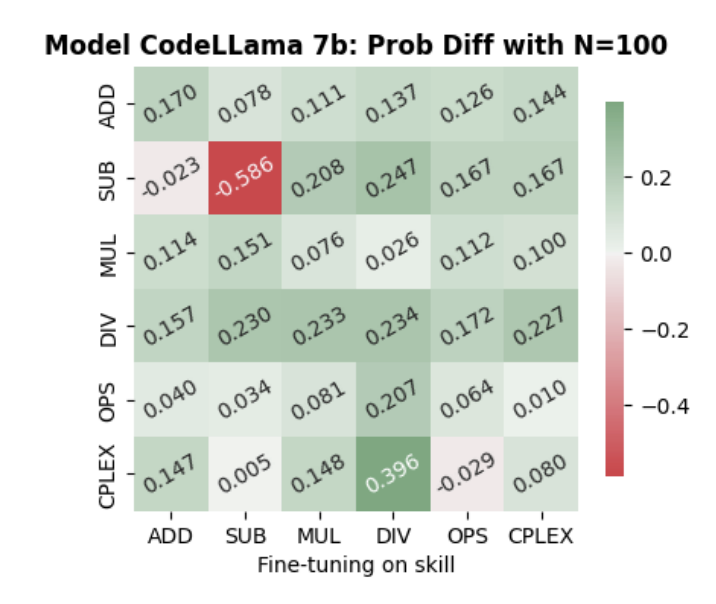
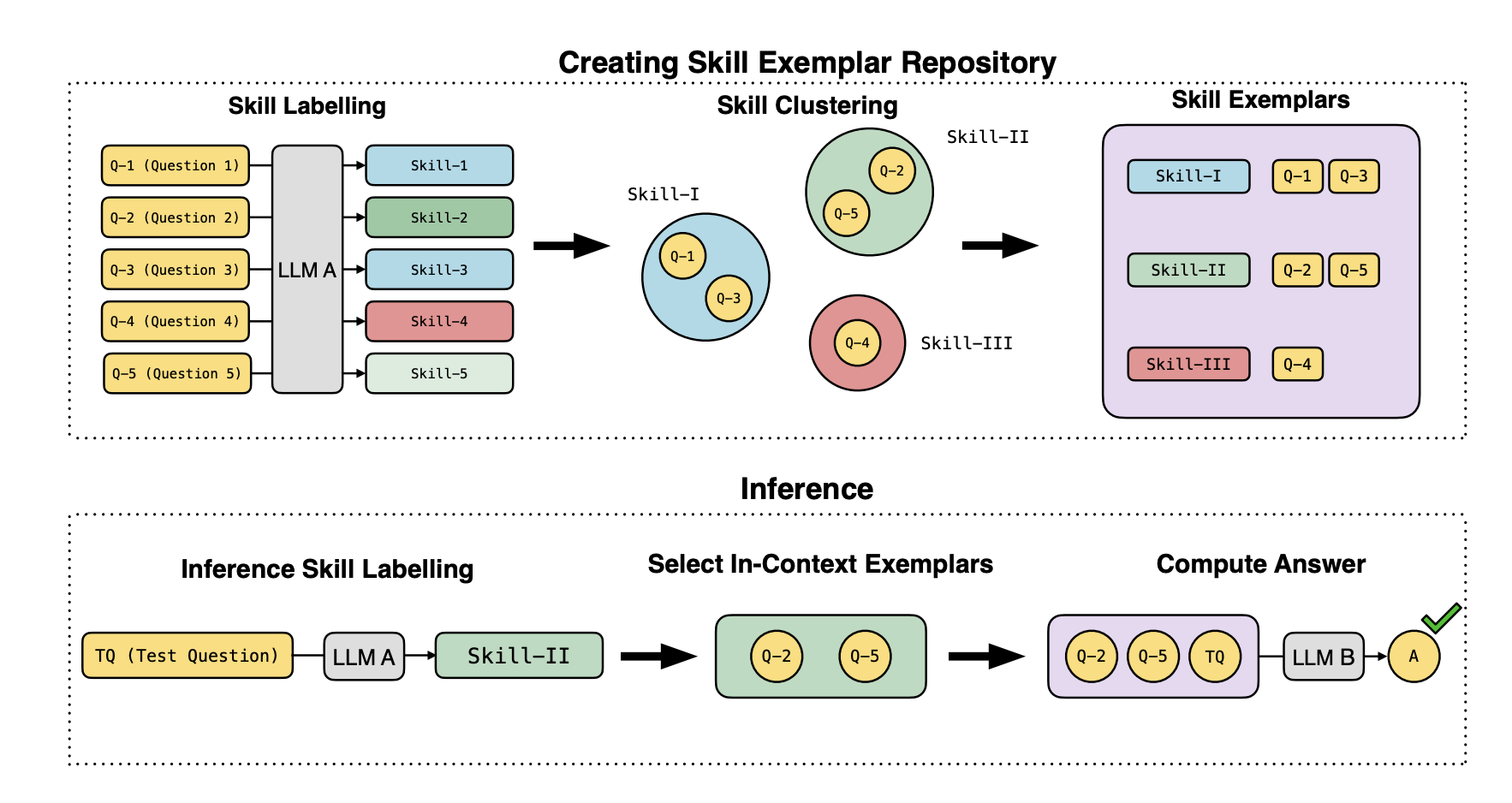
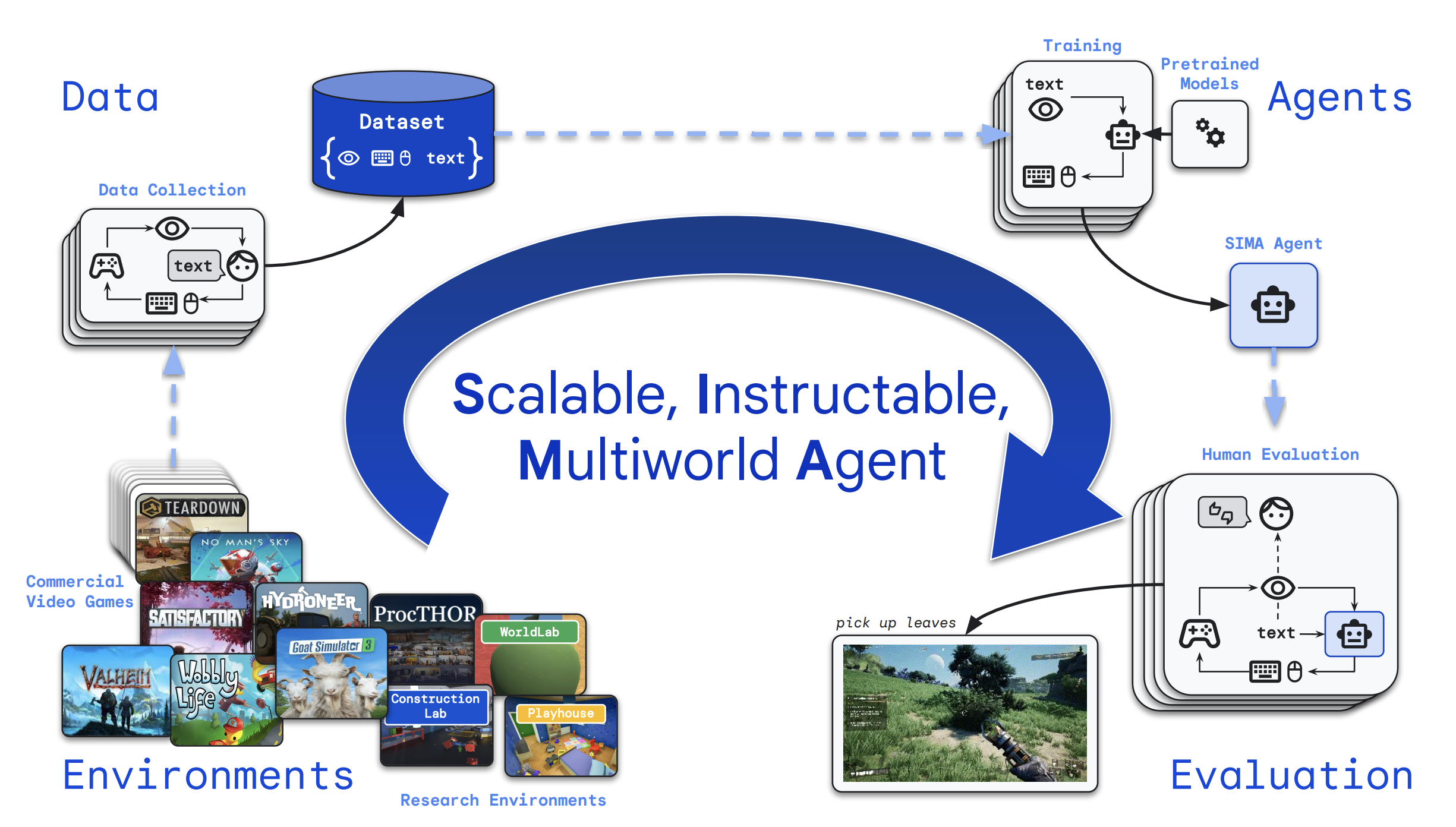
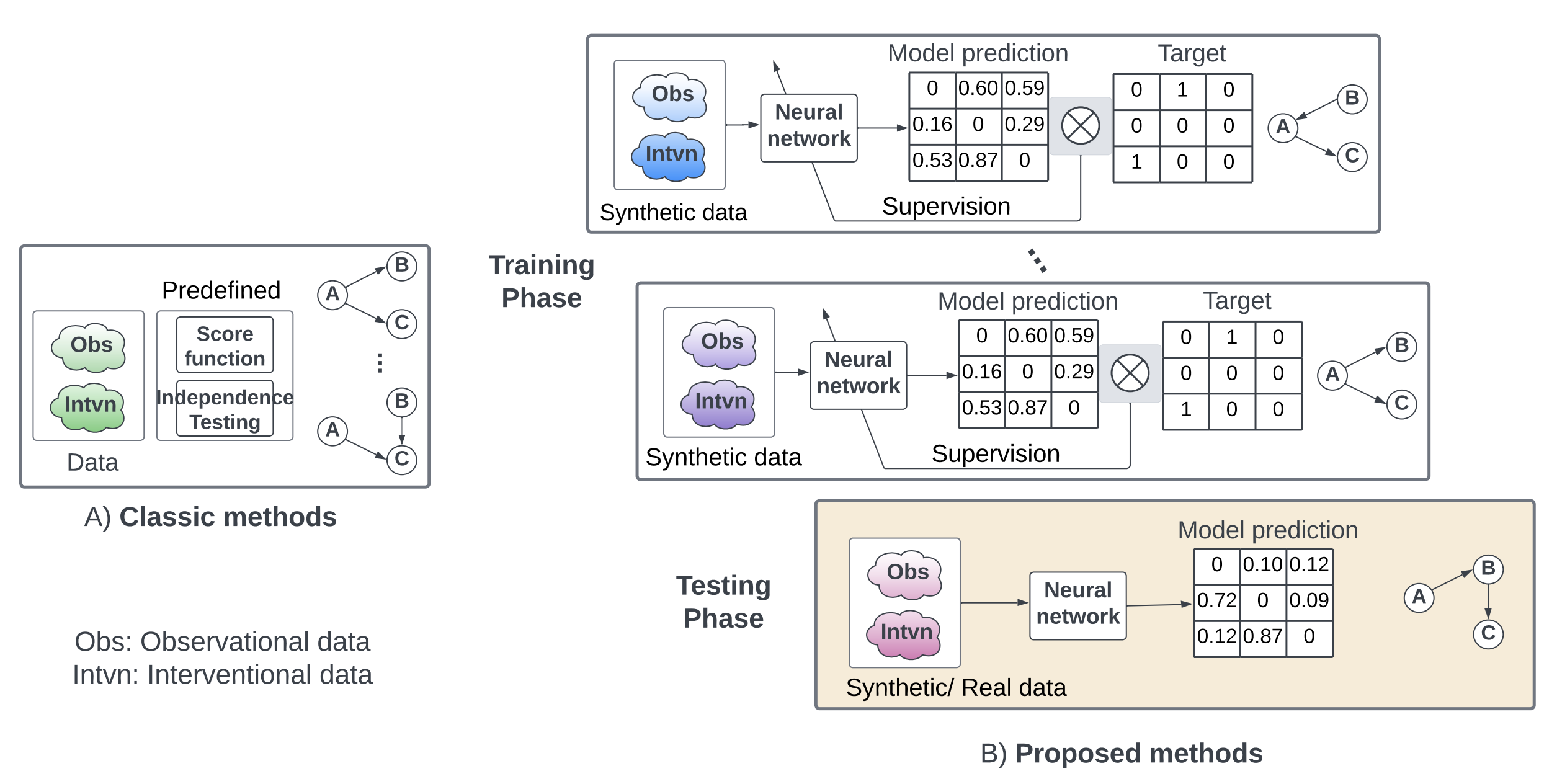
Neural architectures that infer causal graphs from observational and interventional data with strong generalization to new graphs and naturalistic settings.